- Record: found
- Abstract: found
- Article: found
A consensus S. cerevisiae metabolic model Yeast8 and its ecosystem for comprehensively probing cellular metabolism
Read this article at
Abstract
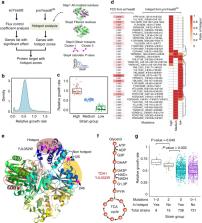
Genome-scale metabolic models (GEMs) represent extensive knowledgebases that provide a platform for model simulations and integrative analysis of omics data. This study introduces Yeast8 and an associated ecosystem of models that represent a comprehensive computational resource for performing simulations of the metabolism of Saccharomyces cerevisiae––an important model organism and widely used cell-factory. Yeast8 tracks community development with version control, setting a standard for how GEMs can be continuously updated in a simple and reproducible way. We use Yeast8 to develop the derived models panYeast8 and coreYeast8, which in turn enable the reconstruction of GEMs for 1,011 different yeast strains. Through integration with enzyme constraints (ecYeast8) and protein 3D structures (proYeast8 DB), Yeast8 further facilitates the exploration of yeast metabolism at a multi-scale level, enabling prediction of how single nucleotide variations translate to phenotypic traits.
Abstract
Genome-scale metabolic models provide a platform to study metabolism through simulations and analysis of omics data. Here the authors introduce Yeast8 with its model ecosystem, a comprehensive computational resource for simulating the metabolism of Saccharomyces cerevisiae.
Related collections
Most cited references46
- Record: found
- Abstract: found
- Article: not found
Comparison of the predicted and observed secondary structure of T4 phage lysozyme.
- Record: found
- Abstract: found
- Article: not found
Quantitative prediction of cellular metabolism with constraint-based models: the COBRA Toolbox v2.0.

- Record: found
- Abstract: found
- Article: found