- Record: found
- Abstract: found
- Article: not found
ToxIBTL: prediction of peptide toxicity based on information bottleneck and transfer learning
Read this article at

Abstract
Motivation
Recently, peptides have emerged as a promising class of pharmaceuticals for various diseases treatment poised between traditional small molecule drugs and therapeutic proteins. However, one of the key bottlenecks preventing them from therapeutic peptides is their toxicity toward human cells, and few available algorithms for predicting toxicity are specially designed for short-length peptides.
Results
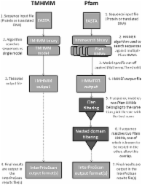
We present ToxIBTL, a novel deep learning framework by utilizing the information bottleneck principle and transfer learning to predict the toxicity of peptides as well as proteins. Specifically, we use evolutionary information and physicochemical properties of peptide sequences and integrate the information bottleneck principle into a feature representation learning scheme, by which relevant information is retained and the redundant information is minimized in the obtained features. Moreover, transfer learning is introduced to transfer the common knowledge contained in proteins to peptides, which aims to improve the feature representation capability. Extensive experimental results demonstrate that ToxIBTL not only achieves a higher prediction performance than state-of-the-art methods on the peptide dataset, but also has a competitive performance on the protein dataset. Furthermore, a user-friendly online web server is established as the implementation of the proposed ToxIBTL.
Related collections
Most cited references40
- Record: found
- Abstract: found
- Article: not found
Gapped BLAST and PSI-BLAST: a new generation of protein database search programs.
- Record: found
- Abstract: found
- Article: found
InterProScan 5: genome-scale protein function classification

- Record: found
- Abstract: found
- Article: found