- Record: found
- Abstract: found
- Article: found
Enhanced mechanisms of pooling and channel attention for deep learning feature maps
Read this article at
Abstract
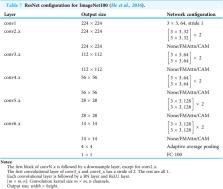
The pooling function is vital for deep neural networks (DNNs). The operation is to generalize the representation of feature maps and progressively cut down the spatial size of feature maps to optimize the computing consumption of the network. Furthermore, the function is also the basis for the computer vision attention mechanism. However, as a matter of fact, pooling is a down-sampling operation, which makes the feature-map representation approximately to small translations with the summary statistic of adjacent pixels. As a result, the function inevitably leads to information loss more or less. In this article, we propose a fused max-average pooling (FMAPooling) operation as well as an improved channel attention mechanism (FMAttn) by utilizing the two pooling functions to enhance the feature representation for DNNs. Basically, the methods are to enhance multiple-level features extracted by max pooling and average pooling respectively. The effectiveness of the proposals is verified with VGG, ResNet, and MobileNetV2 architectures on CIFAR10/100 and ImageNet100. According to the experimental results, the FMAPooling brings up to 1.63% accuracy improvement compared with the baseline model; the FMAttn achieves up to 2.21% accuracy improvement compared with the previous channel attention mechanism. Furthermore, the proposals are extensible and could be embedded into various DNN models easily, or take the place of certain structures of DNNs. The computation burden introduced by the proposals is negligible.
Related collections
Most cited references33
- Record: found
- Abstract: found
- Article: not found
Attention Is All You Need
- Record: found
- Abstract: not found
- Conference Proceedings: not found