- Record: found
- Abstract: found
- Article: found
Comprehensive Analysis of Alternative Splicing Across Tumors from 8,705 Patients

Read this article at
SUMMARY
Our comprehensive analysis of alternative splicing across 32 The Cancer Genome Atlas cancer types from 8,705 patients detects alternative splicing events and tumor variants by reanalyzing RNA and whole-exome sequencing data. Tumors have up to 30% more alternative splicing events than normal samples. Association analysis of somatic variants with alternative splicing events confirmed known trans associations with variants in SF3B1 and U2AF1 and identified additional trans-acting variants (e.g., TADA1, PPP2R1A). Many tumors have thousands of alternative splicing events not detectable in normal samples; on average, we identified ≈930 exon-exon junctions (“neojunctions”) in tumors not typically found in GTEx normals. From Clinical Proteomic Tumor Analysis Consortium data available for breast and ovarian tumor samples, we confirmed ≈1.7 neojunction- and ≈0.6 single nucleotide variant-derived peptides per tumor sample that are also predicted major histocompatibility complex-I binders (“putative neoantigens”).
Graphical Abstract
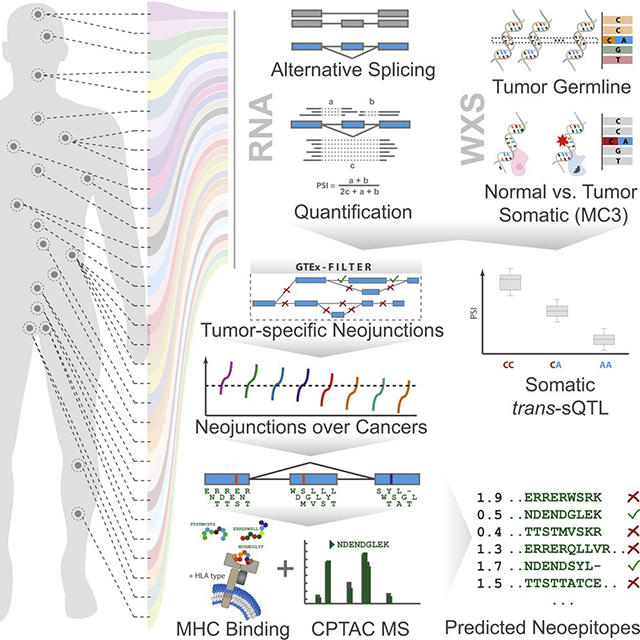
In Brief
A pan-cancer analysis by Kahles et al. shows increased alternative splicing events in tumors versus normal tissue and identifies trans-acting variants associated with alternative splicing events. Tumors contain neojunction-derived peptides absent in normal samples, including predicted MHC-I binders that are putative neoantigens.
Related collections
Most cited references76

- Record: found
- Abstract: found
- Article: found
The Sequence Alignment/Map format and SAMtools
- Record: found
- Abstract: found
- Article: not found
STAR: ultrafast universal RNA-seq aligner.
- Record: found
- Abstract: found
- Article: not found