- Record: found
- Abstract: found
- Article: found
ChatGPT, GPT-4, and Other Large Language Models: The Next Revolution for Clinical Microbiology?
Read this article at
Abstract
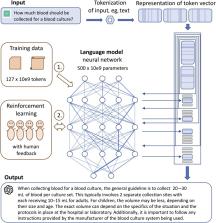
ChatGPT, GPT-4, and Bard are highly advanced natural language process–based computer programs (chatbots) that simulate and process human conversation in written or spoken form. Recently released by the company OpenAI, ChatGPT was trained on billions of unknown text elements (tokens) and rapidly gained wide attention for its ability to respond to questions in an articulate manner across a wide range of knowledge domains. These potentially disruptive large language model (LLM) technologies have a broad range of conceivable applications in medicine and medical microbiology. In this opinion article, I describe how chatbot technologies work and discuss the strengths and weaknesses of ChatGPT, GPT-4, and other LLMs for applications in the routine diagnostic laboratory, focusing on various use cases for the pre- to post-analytical process.
Abstract
Natural language processing–based computer software simulates and processes human conversation. These potentially disruptive large language model technologies have a broad range of conceivable applications in medical microbiology. Strengths and weaknesses for applications in routine diagnostics are discussed.
Related collections
Most cited references39

- Record: found
- Abstract: found
- Article: found
Highly accurate protein structure prediction with AlphaFold
- Record: found
- Abstract: found
- Article: not found