- Record: found
- Abstract: found
- Article: found
Accurate prediction of protein–nucleic acid complexes using RoseTTAFoldNA

Read this article at
Abstract
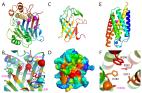
Protein–RNA and protein–DNA complexes play critical roles in biology. Despite considerable recent advances in protein structure prediction, the prediction of the structures of protein–nucleic acid complexes without homology to known complexes is a largely unsolved problem. Here we extend the RoseTTAFold machine learning protein-structure-prediction approach to additionally predict nucleic acid and protein–nucleic acid complexes. We develop a single trained network, RoseTTAFoldNA, that rapidly produces three-dimensional structure models with confidence estimates for protein–DNA and protein–RNA complexes. Here we show that confident predictions have considerably higher accuracy than current state-of-the-art methods. RoseTTAFoldNA should be broadly useful for modeling the structure of naturally occurring protein–nucleic acid complexes, and for designing sequence-specific RNA and DNA-binding proteins.
Abstract
RoseTTAFoldNA extends the RoseTTAFold2 platform to predict the structures of protein–DNA and protein–RNA complexes.
Related collections
Most cited references33

- Record: found
- Abstract: found
- Article: found
Highly accurate protein structure prediction with AlphaFold
- Record: found
- Abstract: found
- Article: not found
Gapped BLAST and PSI-BLAST: a new generation of protein database search programs.
- Record: found
- Abstract: found
- Article: found