- Record: found
- Abstract: found
- Article: found
Musicians Show Improved Speech Segregation in Competitive, Multi-Talker Cocktail Party Scenarios
Read this article at
Abstract
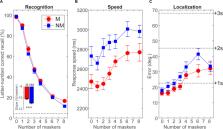
Studies suggest that long-term music experience enhances the brain’s ability to segregate speech from noise. Musicians’ “speech-in-noise (SIN) benefit” is based largely on perception from simple figure-ground tasks rather than competitive, multi-talker scenarios that offer realistic spatial cues for segregation and engage binaural processing. We aimed to investigate whether musicians show perceptual advantages in cocktail party speech segregation in a competitive, multi-talker environment. We used the coordinate response measure (CRM) paradigm to measure speech recognition and localization performance in musicians vs. non-musicians in a simulated 3D cocktail party environment conducted in an anechoic chamber. Speech was delivered through a 16-channel speaker array distributed around the horizontal soundfield surrounding the listener. Participants recalled the color, number, and perceived location of target callsign sentences. We manipulated task difficulty by varying the number of additional maskers presented at other spatial locations in the horizontal soundfield (0–1–2–3–4–6–8 multi-talkers). Musicians obtained faster and better speech recognition amidst up to around eight simultaneous talkers and showed less noise-related decline in performance with increasing interferers than their non-musician peers. Correlations revealed associations between listeners’ years of musical training and CRM recognition and working memory. However, better working memory correlated with better speech streaming. Basic (QuickSIN) but not more complex (speech streaming) SIN processing was still predicted by music training after controlling for working memory. Our findings confirm a relationship between musicianship and naturalistic cocktail party speech streaming but also suggest that cognitive factors at least partially drive musicians’ SIN advantage.
Related collections
Most cited references74
- Record: found
- Abstract: found
- Article: not found
Development of the Hearing in Noise Test for the measurement of speech reception thresholds in quiet and in noise.
- Record: found
- Abstract: found
- Article: not found
'Oops!': performance correlates of everyday attentional failures in traumatic brain injured and normal subjects.
- Record: found
- Abstract: found
- Article: not found